
探索JavaScript模块的循环加载

Table Of Content
场景 🔍
i 在开发迭代的过程中 因为大部分页面都会抽离出可配置项 然后在我进行重构整合的时候 发现了一个始料未及的问题
-
在主配置
A文件中 有一个汇总的枚举值对象在B文件中 此时A---依赖--->B -
然后
B文件又需要读取C文件中的字段映射整合的工具函数 此时B---依赖--->C -
最后
C文件又需要读取A文件中设定好的一些映射字段 此时C---依赖--->A
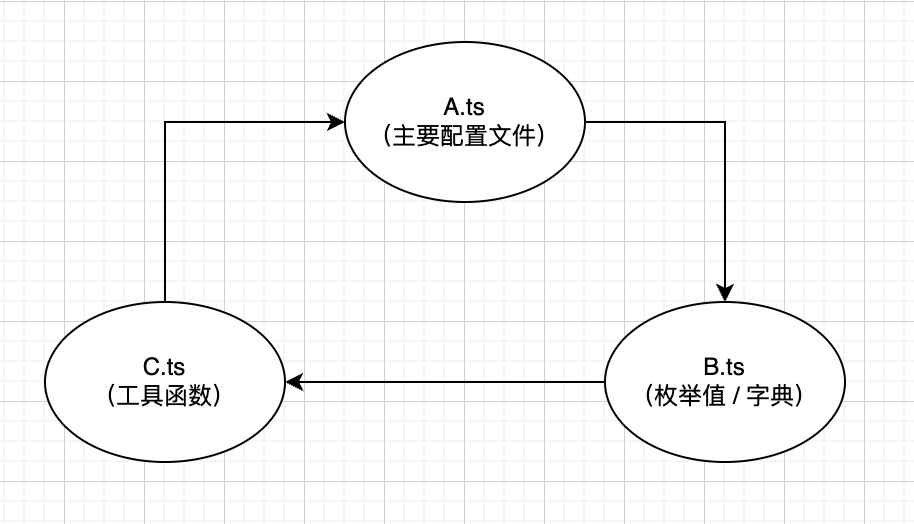
这样就触发了模块中 「循环加载(circular dependency)」 问题

深入浅出CommonJS 🔨
加载模块的原理
CommonJS的一个模块 就是一个脚本文件 require命令第一次加载该脚本 就会执行整个脚本 然后在内存生成一个对象
{
id: '...', // 模块名
exports: { ... }, // 输出的各个接口
loaded: true, // 该模块的脚本是否执行完毕的flag
...
}
上述结构则是加载模块产生的对象 更多字段可参考《require() 源码解读》
- 需要用到这个模块的时候 就会到
exports属性上面取值 - 即使再次执行
require命令 也不会再次执行该模块 而是到缓存之中取值
循环加载
CommonJS模块的重要特性是加载时执行,即脚本代码在require的时候就会全部执行
针对「循环加载」的特殊情况 CommonJS的做法是 就只输出已经执行的部分 还未执行的部分不会输出
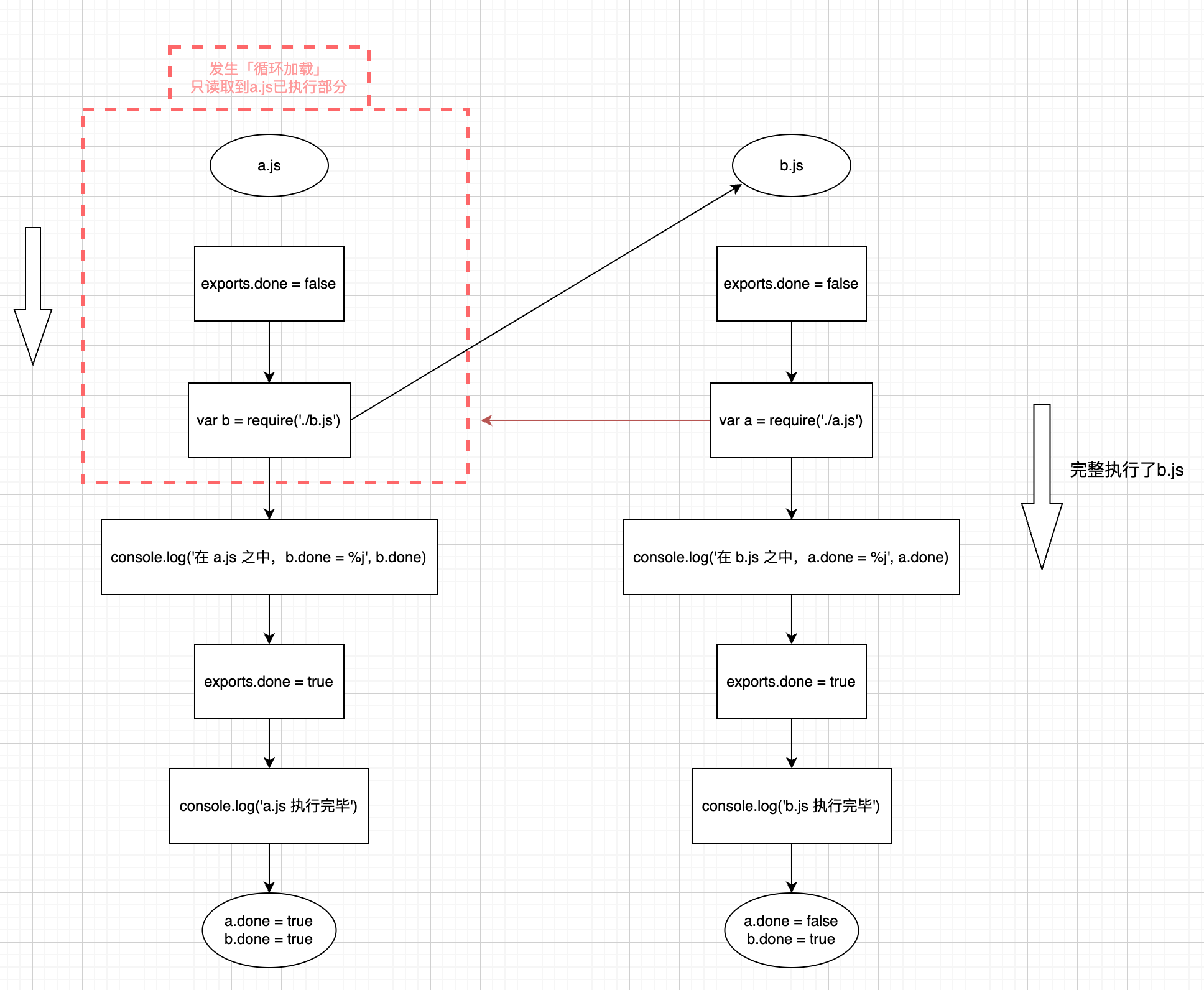
// a.js
exports.done = false;
var b = require('./b.js');
console.log('在 a.js 之中,b.done = %j', b.done);
exports.done = true;
console.log('a.js 执行完毕');
// b.js
exports.done = false;
var a = require('./a.js');
console.log('在 b.js 之中,a.done = %j', a.done);
exports.done = true;
console.log('b.js 执行完毕');
🤔:上述demo 执行node a会打印什么?
在 b.js 之中,a.done = false
b.js 执行完毕
在 a.js 之中,b.done = true
a.js 执行完毕带着之前说过CommonJS循环加载的原理我们来梳理下为什么输出这样的结果
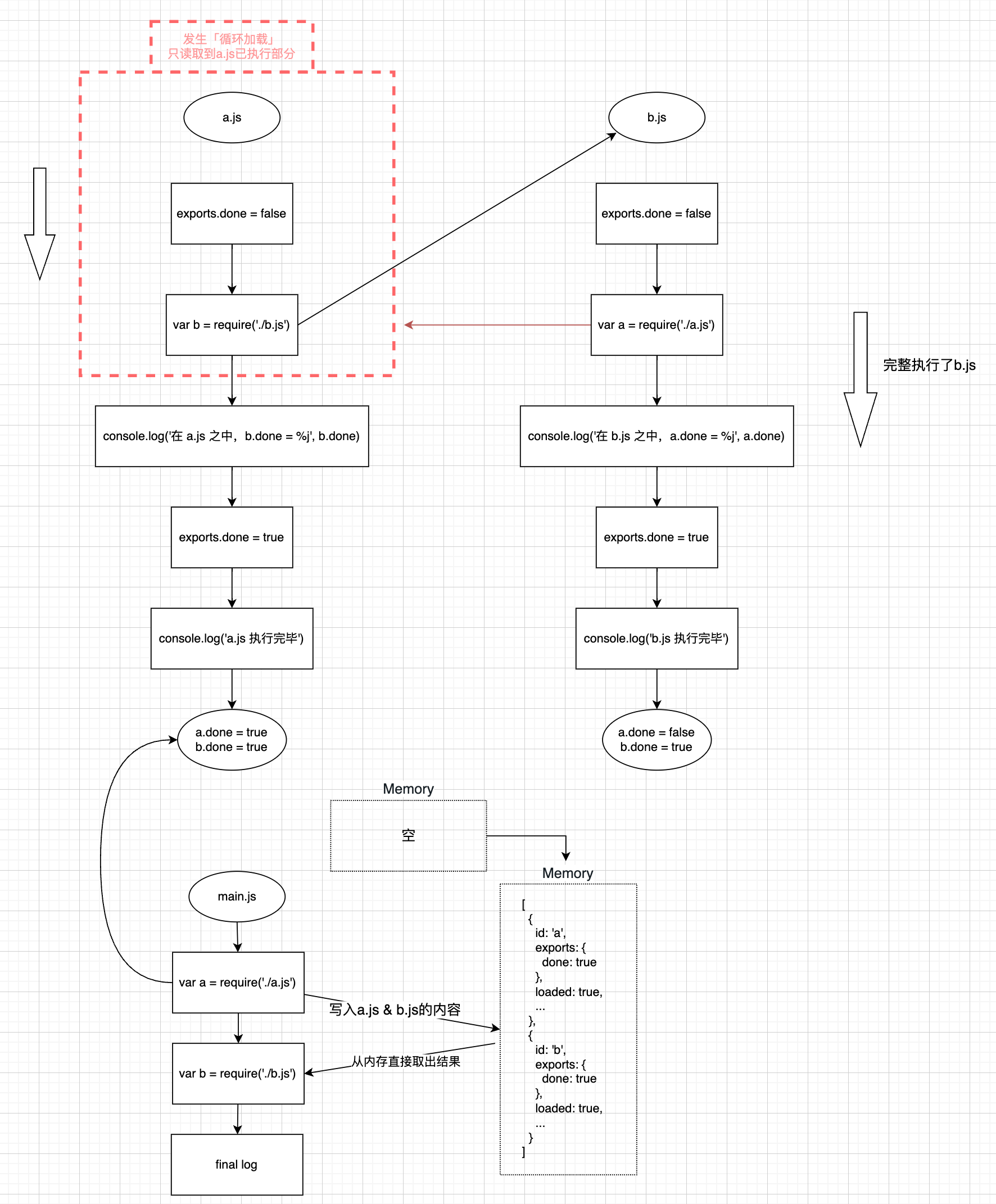
🤔 此时我新增一个main.js来执行上述脚本 最后输出的是什么 & 两者的done字段会有什么变化 带着问题我写了以下内容 ⬇️
// main.js
var a = require('./a.js');
var b = require('./b.js');
console.log('在 main.js 之中, a.done=%j, b.done=%j', a.done, b.done);
执行结果:
在 b.js 之中,a.done = false
b.js 执行完毕
在 a.js 之中,b.done = true
a.js 执行完毕
在 main.js 之中, a.done=true, b.done=true刚看到结果的时候 我有些不解 因为按照我的理解 他应该是输出以下内容 ⬇️
执行结果:
// var a = require('./a.js') 输出的log
在 b.js 之中,a.done = false
b.js 执行完毕
在 a.js 之中,b.done = true
a.js 执行完毕
// var b = require('./b.js') 输出的log
在 b.js 之中,a.done = true
b.js 执行完毕
// main.js 最终的log
在 main.js 之中, a.done=true, b.done=true除了b.js的日志没有输出以外 其他的貌似按照事情的发展进行着 不过为啥没输出成为了困扰我的问题🤔
电光火石之间 我发现我是个小丑🤡 在前面CommonJS的编译原理的时候 提到了一条重要的rule
- 即使再次执行
require命令 也不会再次执行该模块 而是到缓存之中取值
然后一切都释怀了👀

OK 现在梳理下我们的逻辑 main.js的执行顺序就变成了下图 ⬇️
浅入浅出ES Modules 🔧
运行机制
ES6模块遇到加载命令import时 不会去执行模块 而是只生成一个引用 等到真的需要用到时 再到模块里面去取值
因此 ES6模块是动态引用 不存在缓存值的问题 而且模块里面的变量 绑定其所在的模块 举个栗子🌰
CommonJS
// m1.js
let foo = 'bar'
setTimeout(() => {
foo = 'baz'
console.log('foo changed')
}, 500)
exports.foo = foo
// m2.js
const m1 = require('./m1')
console.log('first: ', m1.foo);
setTimeout(() => {
console.log('final: ', m1.foo)
}, 500)
// 输出结果:
// first: bar
// foo changed
// final: bar
ES Modules
// m1.js
export var foo = 'bar';
setTimeout(() => {
foo = 'baz'
}, 500);
// m2.js
import { foo } from './m1.js';
console.log('first: ', foo);
setTimeout(() => {
console.log('final: ', foo)
}, 500);
// 输出结果:
// first: bar
// foo changed
// final: baz
⬆️上述代码表明 ES6模块不会缓存运行结果 而是动态地去被加载的模块取值 以及变量总是绑定其所在的模块
循环加载
ES6根本不会关心是否发生了「循环加载」 只是生成一个指向被加载模块的引用 需要开发者自己保证 真正取值的时候能够取到期望的值
但是对于export导出的是变量 or 函数会改变「循环加载」的逻辑 ⬇️
// a.js
import { bar } from './b.js';
console.log('a.js');
console.log(bar);
export let foo = 'foo'
// b.js
import { foo } from './a.js';
console.log('b.js');
console.log(foo);
export let bar = 'bar';
// 输出结果:
// console.log(foo);
^
// ReferenceError: Cannot access 'foo' before initialization
// at b.js:11:13
Cannot access 'foo' before initialization🤔
然后我检索了网上的相关文章 有一篇文章说将foo改为函数输出则可以解决这个问题 然后我就尝试了一下
// a.js
import { bar } from './b.js';
console.log('a.js');
console.log(bar);
// export let foo = 'foo'
export function foo() {
return 'foo'
}
// b.js
import { foo } from './a.js';
console.log('b.js');
console.log(foo());
export let bar = 'bar';
// 输出结果:
// b.js
// foo
// a.js
// bar
正常输出log✅ 然后根据文章所说的 然后加上我的猜想 梳理的ES Modules的处理逻辑流程如下 ⬇️
-
引擎会优先执行 import 加载的模块 即会优先执行
b.js,然后再执行a.js -
引擎会优先收集 export 暴露的属性并进行类似作用域内的声明 即虽然
foo在运行时没有执行到赋值的逻辑 但是已经在内部生命了该变量***(猜测)*** -
根据以上两点 在执行
b.js的时候 默认读取了a.js暴露的未被初始化的foo属性b.js拿到了该属性后 不会去完整执行a.js认为该属性已存在 则继续往下执行***(猜测)*** -
执行到第三行
console.log(foo)的时候 才发现这个属性只是进行了声明但根本没定义 因此报错 -
下面正常输出的log 是因为函数具有提升作用,在执行
import { bar } from './b.js'时 函数foo就已经有定义了 所以b.js加载的时候不会报错***(猜测)***
-
这里不能将函数定义成函数表达式 如
export const foo = () => ...因为实际上他也是以变量的方式声明出来的 所以一样会提示ReferenceError: Cannot access 'foo' before initialization

思考 🤔
- 首先我觉得这样「循环加载」存在的问题
- 循环加载 直观的体现出来了逻辑的强耦合
- 递归加载 使程序瘫痪的可能性大大增加
- 接着关于「模块/配置化」我想说的
- 理想中的优点:
- 职责单一 不需要关注当前配置/模块负责的额外逻辑
- 模块间解耦 供相似需求的地方复用 提高开发效率
- 直观 可以迅速找出所需模块
- 在复杂的大项目中 我们对这些地方进行重构或后续开发 就带来了以下问题
- 当产生一条模块链的时候 没有关注每个模块的细节 我根本不知道在哪个模块下叉出来一个分支 引用了链中的模块 最终无意识地造成了「循环加载」🤨
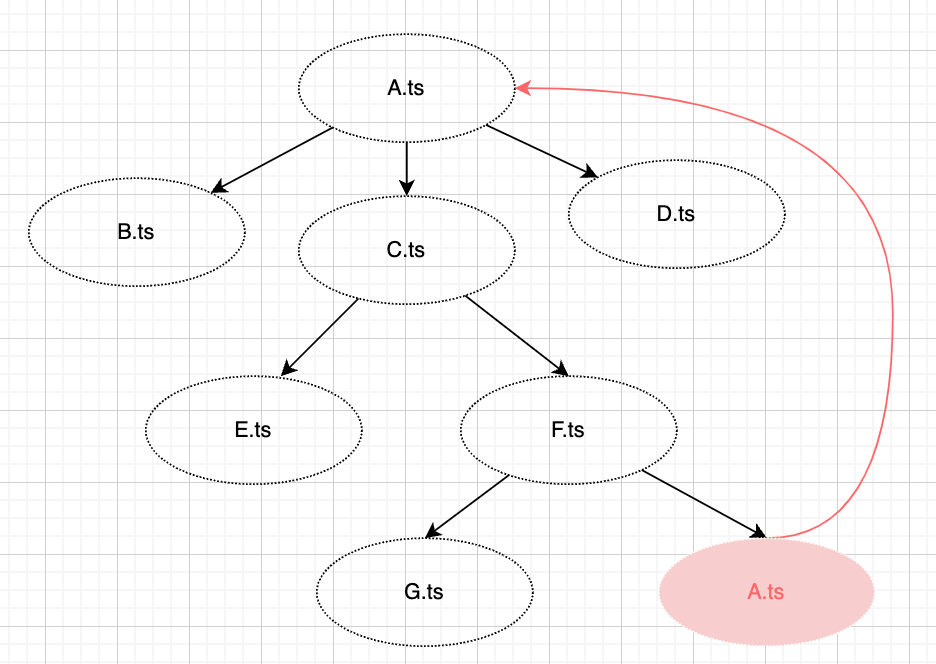

-
过度的「模块配置化」 就是在提高理解成本的同时 还带来了维护上的问题 不知道怎么下手 😵💫
-
计划赶不上变化 只能适应特定时期的业务场景 配置化和拓展性结合的时候总是显得那么捉襟见肘 🤯
-
以上仅代表我个人的观点 我觉得这一直都是仁者见仁 智者见智的东西 不可否认的是「模块/配置化」在给我们开发带来便利的同时 无形中又给我们增加些许的成本 😬
-
希望大佬们以后有遇到这样「循环加载」的问题的时候也可以有所帮助 end 🫡
最后 想问下大佬们有没有对ES Modules更深层次的理解 欢迎讨论👏👏